



Introduction
Hello again! That's Felipe here, and today we will focus in specials weapons for developers who want to fast build and deploy endpoints, to GET/POST/PUT/DELETE information on a database regarding data of some application. This topic is really valuable for IoT systems, because with these tools you are capable of fast deploy an endpoint, then turning it available to devices to send information about sensors, calculations and any other kind of data that would be important for your application. We also have a video detailing all this tutorial, if a video approach is better for you, you can see it here:
The importance of serverless applications are getting higher each day, and inasmuch the technology is evolving, the capability of generating faster and reliable applications is also getting bigger. Therefore, even though many applications still rely in managed and provisioned servers, the cloud available services offers a cheap and secured environment, so thats the reason will so many huge companies are migrating great part of their infrastructure to the cloud.
These new available tools are not only a profitable option for companies, but also for single developers who works as a self employed professional, or people trying to learn these new services. Early, it was extremelly difficult to a person having it's own server connected to the internet, mainly because of the hardware and network infrastructure.
So summarizing, this is a basic tutorial regarding three awesome services from amazon, and how to use then with Python language. The AWS services are:
- API Gateway - This service is responsible for deploying and serving HTTP RESTful endpoints. Thus you can trigger actions, when HTTP calls arrives to the generated endpoints.
- Lambda - This let you run code without provisioning or managing servers.
- DynamoDB - The NoSQL amazon database, where you can insert the information of your application on tables (Collections).
So let's first talk more about what are these three services, and after that delve into our example.
AWS API Gateway
Amazon API Gateway is an AWS service that enables you to create, publish, maintain, monitor, and secure your own REST and Websocket APIs at any scale. You can create robust, secure, and scalable APIs that access AWS or other web services, as well as data stored in the AWS cloud. You can create APIs for use in your own client applications (apps). Or you can make your APIs available to third-party app developers.
AWS Lambda
AWS Lambda is a compute service that lets you run code without provisioning or managing servers. AWS Lambda executes your code only when needed and scales automatically, from a few requests per day to thousands per second. You pay only for the compute time you consume - there is no charge when your code is not running. With AWS Lambda, you can run code for virtually any type of application or backend service - all with zero administration. AWS Lambda runs your code on a high-availability compute infrastructure and performs all of the administration of the compute resources, including server and operating system maintenance, capacity provisioning and automatic scaling, code monitoring and logging. All you need to do is supply your code in one of the languages that AWS lambda supports.
You can use AWS Lambda to run your code in response to events, such as changes to data in an Amazon S3 bucket or an Amazon DynamoDB table; to run your code in response to HTTP requests using Amazon API Gateway; or invoke your code using API calls made using AWS SDKs. With these capabilities, you can use Lambda to easily build data processing triggers for AWS services like Amazon S3 and Amazon DynamoDB, process streaming data stored in Kinesis, or create your own back end that operates at AWS scale, performance, and security.
AWS DynamoDB
Amazon DynamoDB is a fully managed NoSQL database service that allows to create database tables that can store and retrieve any amount of data. It automatically manages the data traffic of tables over multiple servers and maintains performance. It also relieves the customers from the burden of operating and scaling a distributed database. Hence, hardware provisioning, setup, configuration, replication, software patching, cluster scaling, etc. is managed by Amazon.
Why Python?
Today these are the list of languages that AWS Lambda supports:
- Java
- Go
- PowerShell
- Node.js
- C#
- Python
- Ruby
We've selected python most because this is a basic tutorial, and Python was developed in the late 1980s as a language that would be more intuitive and human-readable than languages like C++. Generally speaking, C++ is considered more complicated, error-prone, and closer to being a low-level language. On the totem pole of user-friendliness, this puts C++ near the bottom where actual CPU machine code lives.
So we are selecting python because is very user friendly, and I still use that for my functions because it's really fast to test and to create a function. Then, after everything is explained we are good to go to our example.
IoT Temperature Device Example
So, let's imagine that we have a raspberry pi with a temperature sensor on our room, and we want to save the data every hour in a database where an android/Ios app will get these information and display to an user. One of the most simplest way is making an HTTP request every hour passing through the request body the temperature we want to save in the database. So let's first create the dynamodb table where the information will be saved.
Creating the DynamoDB Table
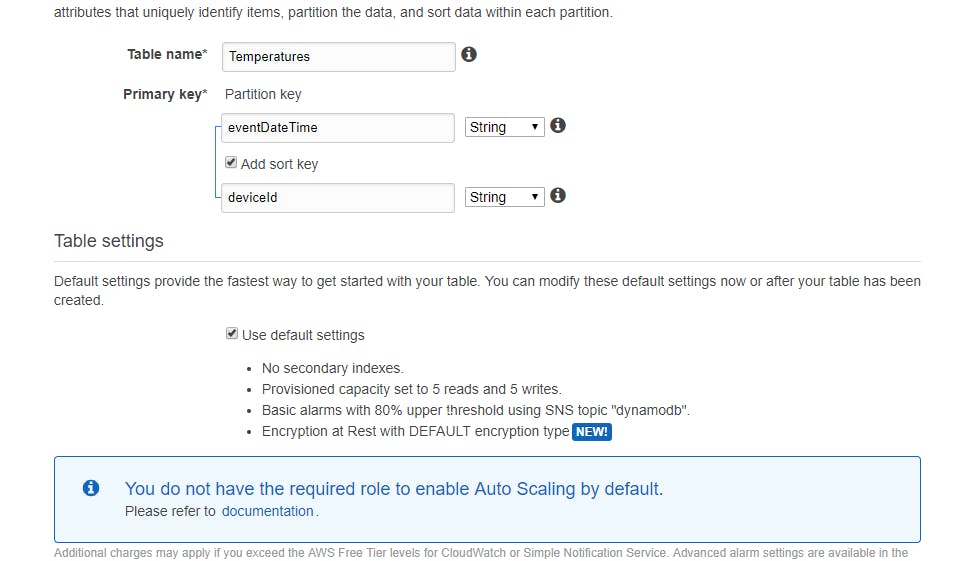
This table will have save the temperature of a current device, so we will create three fields(Columns) to this table:
- eventDateTime - The event timestamp
- deviceId - An unique id for the device that is sending the information
- temperature - The current temperature measured by a sensor So, the first thing we have to do is going to DynamoDB on AWS console, and create a table:
The partition key of this table will be the eventDateTime because they are always unique and can not be repeated, and for sort key we will use the deviceId for helping us to filter information in a faster way. But what is partition key and sort key of a table?
Partition key and sort key – Referred to as a composite primary key, this type of key is composed of two attributes. The first attribute is the partition key, and the second attribute is the sort key.
DynamoDB uses the partition key value as input to an internal hash function. The output from the hash function determines the partition (physical storage internal to DynamoDB) in which the item will be stored. All items with the same partition key value are stored together, in sorted order by sort key value.
In a table that has a partition key and a sort key, it's possible for two items to have the same partition key value. However, those two items must have different sort key values.
So let's create the table like the image bellow:
Different from relational databases, we don't need to create the others table's columns, we only need to include this column as one of the attributes of the json passed to the lambda function, like the example:
{
eventDateTime: "06-03-2019 20:25:01",
deviceId: "61234AFT",
temperature: 30
}
Now that the table is ready, we will create the lambda function to persist data into this table, and another function to gather information about this table. Thus, we will make a lambda function for a POST HTTP request, and a GET HTTP request.
Creating Lambda Function for POST Request
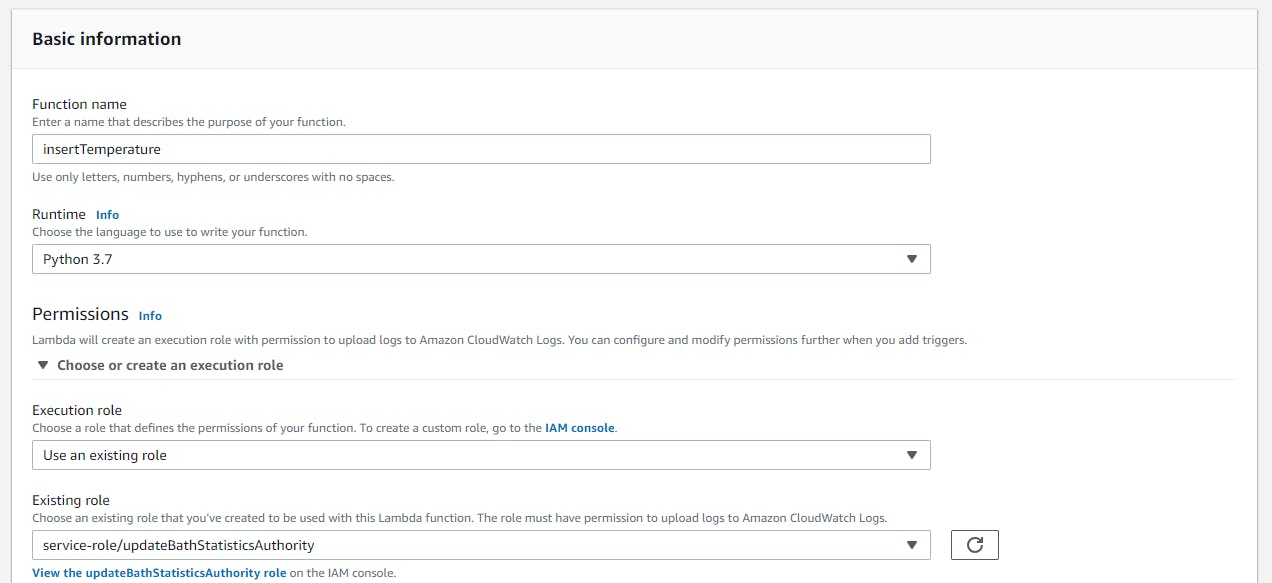
So, now we are ready to create de POST Python Lambda function, thus let's access the lambda console on our aws console, and select to create a function:
After that, a page with some information to select will appear, and you will have to select the python language for your lambda function, don't forget to give it a name (insertTemperature). If you don't have created an IAM role yet, you can choose to create one now. The IAM is the Identinty Access Management** service that manages and coordinates all the access that your user has in AWS Services, all which services can call another services. After that you can check if everything is correct, and let's go to the code!
The next code is already tested and it's working, I put some comments explaining each step:
import json
import boto3
from datetime import datetime
#That's the lambda handler, you can not modify this method
# the parameters from JSON body can be accessed like deviceId = event['deviceId']
def lambda_handler(event, context):
# Instanciating connection objects with DynamoDB using boto3 dependency
dynamodb = boto3.resource('dynamodb')
client = boto3.client('dynamodb')
# Getting the table the table Temperatures object
tableTemperature = dynamodb.Table('Temperatures')
# Getting the current datetime and transforming it to string in the format bellow
eventDateTime = (datetime.now()).strftime("%Y-%m-%d %H:%M:%S")
deviceId = event['deviceId']
temperature = event['temperature']
# Putting a try/catch to log to user when some error occurs
try:
tableTemperature.put_item(
Item={
'eventDateTime': eventDateTime,
'deviceId': deviceId,
'temperature': int(temperature)
}
)
return {
'statusCode': 200,
'body': json.dumps('Succesfully inserted temperature!')
}
except:
print('Closing lambda function')
return {
'statusCode': 400,
'body': json.dumps('Error saving the temperature')
}
Some important comments of the code:
- We are using the boto3 dependency for doing the database persistance, you can check more about this library here: boto3.amazonaws.com/v1/documentation/api/la..
- You can test your code using the lambda console, for example:
I've created the current test:
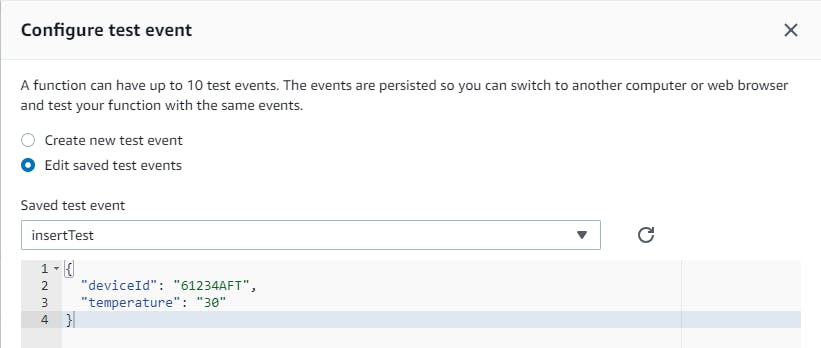
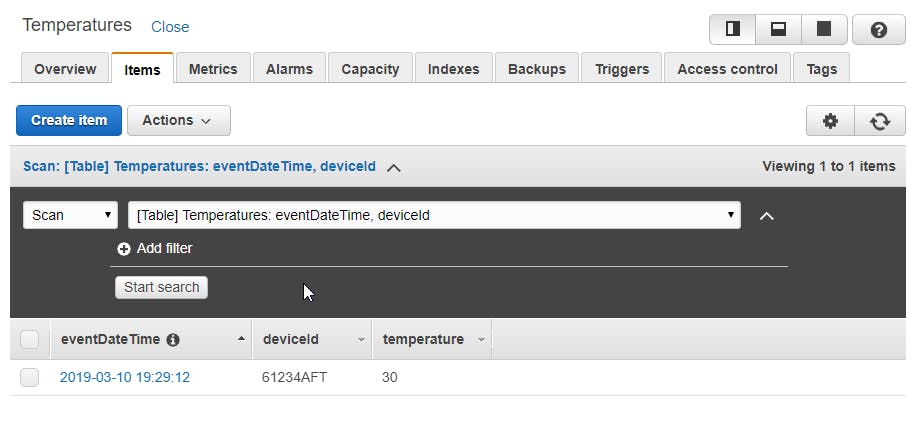
I can configure the test events in your lambda console, so these test events will represent the JSON request body with the information that your lambda function will process, and further save it on the database. Then, I've executed the test, and now I can see the new record in the DynamoDB table:
So now that our function is working, we are good to go to API Gateway to specify an endpoint, and test this API with a HTTP request.
API Gateway Endpoint for POST Request
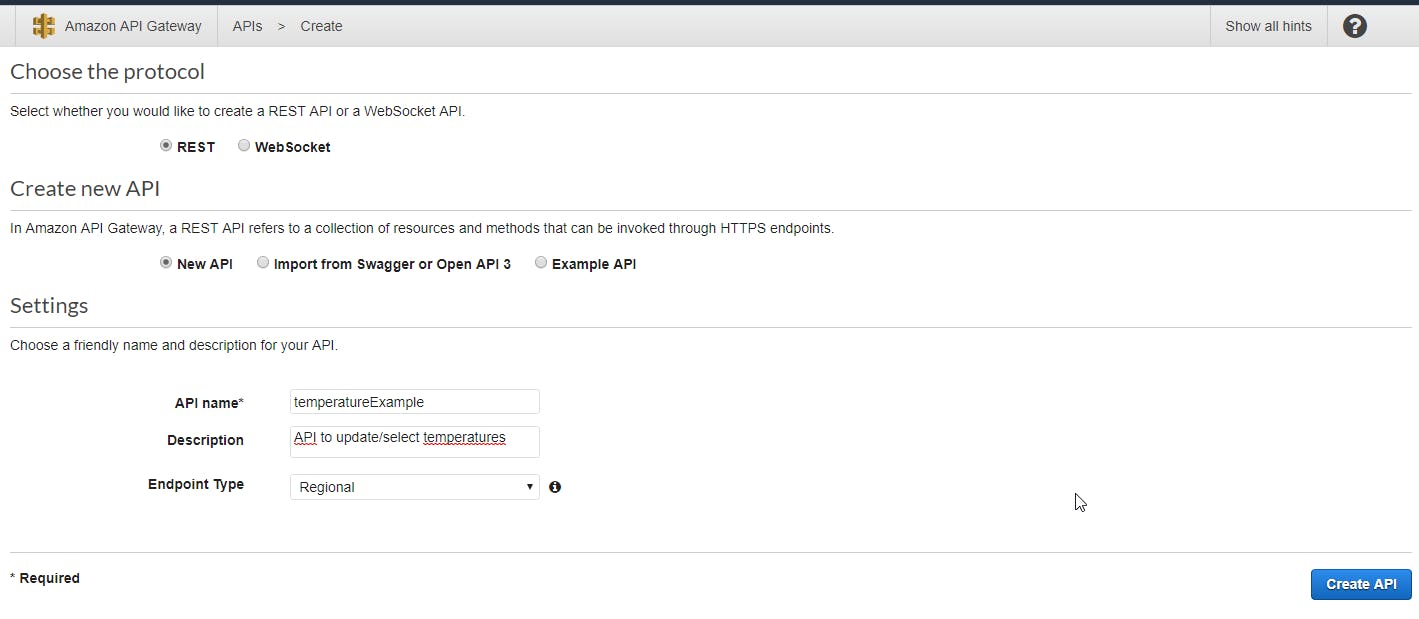
So now, let's go to API Gateway on amazon console, and hit the button to create and endpoint. You will reach a page, and you will need to select the REST(HTTP) protocol, and give a name to the API(temperatureExample), like the example bellow:
After that, you will be directed to the API you have created, and now you can create a POST endpoint for this API on the button Actions-> Create Method.
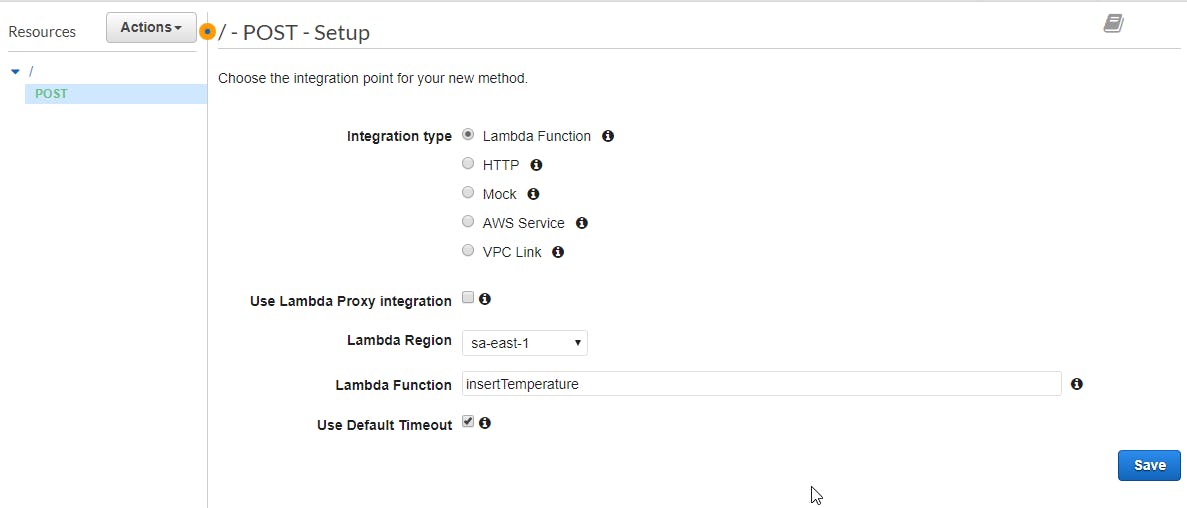
If you have done it correctly, you will be able to find a box with the lambda region, and the lambda function. Remember that in AWS some services are linked with the availability zone that they were created. If you don't know which availability zone you are, you can look in the top of the console, like this example:

You can test the API you have created in the console, but now we will test it after it's deployed. So go to Actions -> Deploy API, you can put any deployment stage you want, and you will receive an url. Pick that one and let's test it in a real HTTP request!
Testing the POST API
There are several tools for testing API, like Postman, but my favorite one is Restlet. It's a chrome extension where you can test your APIs:
So, pick the URL that you've deployed, and test it with an HTTP Post request, with the temperature and device Id in the JSON request body. My test using Restlet was successful!
Creating Lambda Function for GET Request
Now the difficult part of the project has gone, our POST API is done, therefore we can insert many data as we want in AWS. But, if I want to receive all the temperatures in the table ? I will have to do a GET request on our API. Then, our work now is to create the lambda function for filtering all the records of the Temperatures table, and create the GET method on the API Gateway.
So, create a new lambda function called getTemperatures, and the python will look like:
import json
import boto3
def lambda_handler(event, context):
# TODO implement
dynamodb = boto3.resource('dynamodb')
tableTemperatures = dynamodb.Table('Temperatures')
response = tableTemperatures.scan()
return {
'statusCode': 200,
'body': response['Items']
}
That's a very easy piece of code, as we are getting all the records in the table, we just need to call the method .scan( ).
Then, if we deploy again the API Gateway, We can see that now we can get all the temperatures using Restlet:
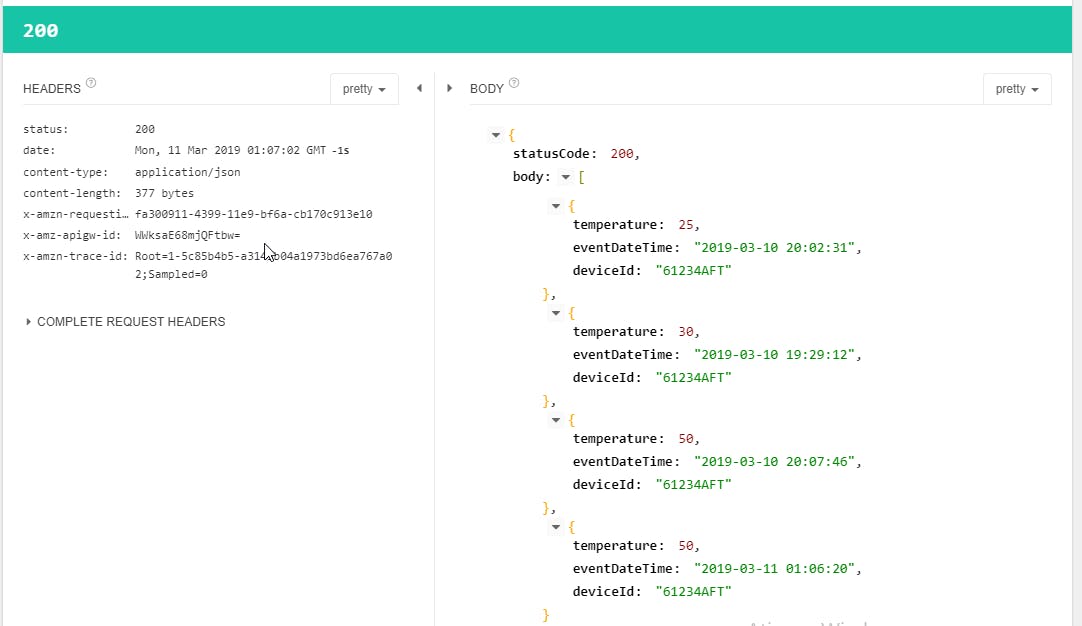
So that's it, now you can fast deploy your APIs using AWS, which turns the production of applications very fast. Imagine a simple mobile aplication that needs some rest endpoints. Withouth the power of lambda, we would have to deploy it on a server or container, which brings a lot of trouble.
Thanks for reading this article, and if you have any doubt, or something to add to this article, just ping me!